There are four ways to manage bodies of codified knowledge - tagging, collection, curation and synthesis. We can illustrate this by looking at lesson learned systems.
Imagine your organisation has been documenting lessons from projects for years, and storing the documented lessons in untagged project reports and project files. This is the default for many organisations starting out with KM.
A first step would be to tag all documents which contain lessons with a #lessons tag. With a good search engine, you would then be able at least to find all documents with lessons content.
The next step would be to collect the lessons and to store them in one place, such as a lessons database or (even better) a lessons management system. This is significantly more convenient than leaving them in project files, as there now becomes one place to go to find lessons, rather than having to open each project report in turn. However by the time there are 1000 or more lessons in the database, it can become a real chore to find anything of value (which is why lesson management systems are better than a passive database).
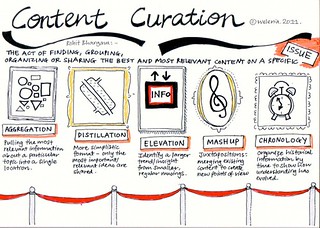
The third step is to curate the lessons. As the diagram here suggests, curation involves different ways of selecting and displaying content; high-grading the important lessons and giving them prominence, grouping similar lessons together, removing duplicates, and so on. This makes it easier for people to find the most relevant and most important lessons. However the user still needs to look through the lessons one by one, and may find contradictions. And curation does not involve changes to the content, merely ways of organising and promoting the content.
The final step is to synthesise the lessons. This involves taking the knowledge from the lessons, and combining it into guidance. Imagine you have 50 lessons on project scoping - you extract the key content from the lessons and build guidelines on project scoping. Then, as new project scoping lessons are identified, the guidelines can be continuously updated and improved. The user then only needs to look at the guidelines, which will contain the synthesised knowledge.
The third step is to curate the lessons. As the diagram here suggests, curation involves different ways of selecting and displaying content; high-grading the important lessons and giving them prominence, grouping similar lessons together, removing duplicates, and so on. This makes it easier for people to find the most relevant and most important lessons. However the user still needs to look through the lessons one by one, and may find contradictions. And curation does not involve changes to the content, merely ways of organising and promoting the content.
The final step is to synthesise the lessons. This involves taking the knowledge from the lessons, and combining it into guidance. Imagine you have 50 lessons on project scoping - you extract the key content from the lessons and build guidelines on project scoping. Then, as new project scoping lessons are identified, the guidelines can be continuously updated and improved. The user then only needs to look at the guidelines, which will contain the synthesised knowledge.
Imagine an engineer looking for best practice for safety procedures for installing gas turbines:
- In the default state, she would need to search across many document systems and folders;
- After step 1 she could at least search for documents tagged "gas turbine" and "safety";
- After step 2 she would know there was a collection of safety documents, and may find several documents she can refer to. She will need to read each one to see which is obsolete and which is useful;
- After step 3 she might find a curated set of safety documents, with the most recent or useful one(s) highlighted, with obsolete documents tagged as such;
- After step 4 she may find a wiki page or procedure entitled "best practice safety procedure, gas turbine installation". After she performs the job, she can share her own lessons in case this procedure needs to be further improved.
The current organisational application of these steps in the management of documented knowledge is shown below (replicated from this blog post - follow the link for more detail).

Steps 1 and 2 represent the dark blue and red sections, step 3 represents the purple section, and step 4 the light blue (upper) section. The three columns represent increasing levels of maturity of the KM program; from early stages to fully embedded.
The plot shows three main things:
- As KM progresses, it becomes far less common to see documented knowledge scattered across many document stores, as people begin to take steps 1 and 2 (tagging and collection).
- As KM progresses it becomes far more common to see documented knowledge being curated and/or synthesised, as organisations take step 3 and step 4.
- Curation and Synthesis are still, unfortunately, minority activities. The majority of organisations responding to the surveys have not passed step 2, even when KM is fully embedded.



No comments:
Post a Comment